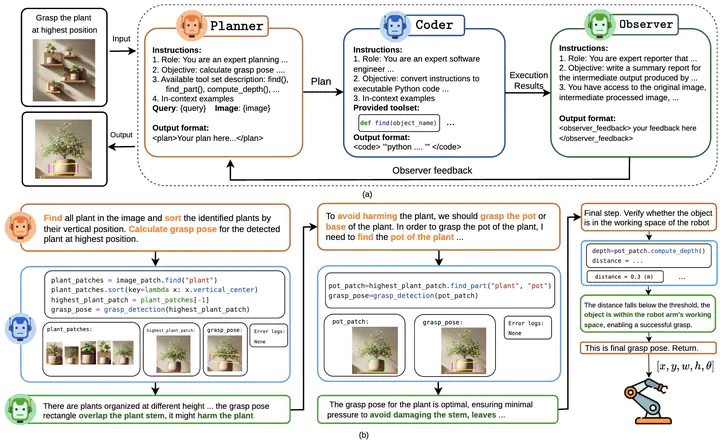
 (a) An overview of our GraspMAS framework, a multi-agent system for zero-shot language-driven grasp detection. GraspMAS consists of three agents: Planner (orange box) – controls the reasoning flow; Coder (blue box) – executes instructions using the provided toolset; and Observer (green box) – evaluates results and provides feedback to the Planner; (b) A successful example demonstrating how our framework enables reasoning grasp detection by leveraging multi-agents knowledge and commonsense understanding.
(a) An overview of our GraspMAS framework, a multi-agent system for zero-shot language-driven grasp detection. GraspMAS consists of three agents: Planner (orange box) – controls the reasoning flow; Coder (blue box) – executes instructions using the provided toolset; and Observer (green box) – evaluates results and provides feedback to the Planner; (b) A successful example demonstrating how our framework enables reasoning grasp detection by leveraging multi-agents knowledge and commonsense understanding.Abstract
Language-driven grasp detection has the potential to revolutionize human-robot interaction by allowing robots to understand and execute grasping tasks based on natural language commands. However, existing approaches face two key challenges. First, they often struggle to interpret complex text instructions or operate ineffectively in densely cluttered environments. Second, most methods require a training or fine-tuning step to adapt to new domains, limiting their generation in real-world applications. In this paper, we introduce GraspMAS, a new multi-agent system framework for language-driven grasp detection. GraspMAS is designed to reason through ambiguities and improve decision-making in real-world scenarios. Our framework consists of three specialized agents- Planner, responsible for strategizing complex queries; Coder, which generates and executes source code; and Observer, which evaluates the outcomes and provides feedback. Intensive experiments on two large-scale datasets demonstrate that our GraspMAS significantly outperforms existing baselines. Additionally, robot experiments conducted in both simulation and real-world settings further validate the effectiveness of our approach. Our project page is available at https://zquang2202.github.io/GraspMAS.
Supplementary notes can be added here, including code, math, and images.