Lightweight language-driven grasp detection using conditional consistency model
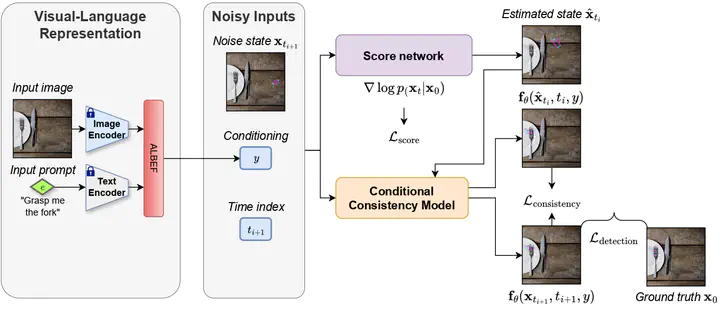 The overview of our method. First, the input RGB image and text prompt are fed into the feature encoder and ALBEF fusion. Subsequently, we concurrently train two models with the same architectures: A score network to estimate the probability flow Ordinary Differential Equation (ODE) trajectory for the diffusion process and a conditional consistency model to determine the grasp pose with a few denoising steps.
The overview of our method. First, the input RGB image and text prompt are fed into the feature encoder and ALBEF fusion. Subsequently, we concurrently train two models with the same architectures: A score network to estimate the probability flow Ordinary Differential Equation (ODE) trajectory for the diffusion process and a conditional consistency model to determine the grasp pose with a few denoising steps.Abstract
Language-driven grasp detection is a fundamental yet challenging task in robotics with various industrial applications. In this work, we present a new approach for language-driven grasp detection that leverages the concept of lightweight diffusion models to achieve fast inference time. By integrating diffusion processes with grasping prompts in natural language, our method can effectively encode visual and textual information, enabling more accurate and versatile grasp positioning that aligns well with the text query. To overcome the long inference time problem in diffusion models, we leverage the image and text features as the condition in the consistency model to reduce the number of denoising timesteps during inference. The intensive experimental results show that our method outperforms other recent grasp detection methods and lightweight diffusion models by a clear margin. We further validate our method in real-world robotic experiments to demonstrate its fast inference time capability.
Supplementary notes can be added here, including code, math, and images.